
di Dan Pejeroni [Infosphere]
Come realizzare nella pratica un ambiente di Sentiment Analysis. Dalla selezione delle possibili sorgenti dati, alla scelta dei componenti nell’ecosistema Hadoop. Come scegliere quale ambiente adottare per l’elaborazione (in-house o in-cloud) e infine qualche algoritmo di base per il calcolo dei risultati.
Marketing e Sentiment Analysis
Prima che l’affermazione dei big data fornisse una concreta capacità di osservazione analitica sul mercato, gli uffici marketing spesso improvvisavano, per poi porsi domande a cui era difficile dare risposte: dove hanno funzionato le campagne? Chi hanno raggiunto? Quale è stata la reazione dei nostri clienti?
Oggi i big data hanno cambiato il paradigma funzionale da: azioni stimate a scelte predittive guidate dai dati. Lo sviluppo della sentiment analysis come strumento di marketing, cioè la tecnologia per determinare il tono emozionale delle opinioni online sui brand, compie un ulteriore passo avanti. Questa scienza, conosciuta anche come opinion mining, utilizza nuove tecnologie e algoritmi per raccogliere e analizzare i dati che rappresentano la percezione di un prodotto, di un servizio o di un intero brand. Non si tratta solo di opinioni, ma attitudini ed emozioni espresse attraverso ogni menzione online. La sentiment analysis cerca di comprendere cosa la gente pensa, non solo cosa dice.
Mettiamo in pratica la Sentiment Analysis
L’analisi del sentiment si basa sull’elaborazione in tempo reale di stream di dati prelevati da una o più piattaforme social media, dove i singoli messaggi, che rappresentano informazioni di stato degli utenti (tweets, post), vengono valutati rispetto a parole chiave (hashtag, keyword) e dizionari, per associarli infine ad una di tre diverse polarità: “neutrale”, “positivo” o “negativo”. Si consideri che il solo public stream di Twitter, produce un volume di oltre 6000 messaggi al secondo.
L’insieme di queste informazioni viene comunemente definito Big Data e la sua analisi consente di ricavare efficaci previsioni di marketing, orientamento politico o trend sociale, poiché rappresenta direttamente il punto di vista delle masse.
Per realizzare un sistema di questo tipo è necessario disporre di:
- Una o più sorgente dati dai social media;
- Una tecnologia in grado di gestire in tempo reale un’enorme volume di dati, contenendo ragionevolmente i costi di implementazione e di gestione;
- Un ambiente di elaborazione in-house o in-cloud;
- Una o più strategie di analisi statistica, data mining e dizionari per il calcolo dei risultati.
Nei prossimi capitoli proveremo a dare una risposta concreta a queste tre esigenze.
1. Le sorgenti dei dati social media
1.1 Le API dei Social Network
Per effettuare la raccolta dei dati dai social network, è possibile oggi una scelta tra diverse strategie:
Accesso tramite API (Application Programming Interface).
Le API sono messe a diposizione dalle stesse piattaforme. Il vantaggio di questo approccio è senza dubbio la possibilità di costruire strumenti ad hoc, per procedere alla raccolta di informazioni secondo le proprie esigenze. D’altro canto lo svantaggio è costituito dal fatto di dipendere dalle decisioni delle piattaforme, per quanto riguarda i dati ai quali accedere e in quale modo.
Per esempio Twitter fornisce una serie di API (Streaming API e Search API) che permettono di raccogliere una grande quantità di informazioni, ma impone limiti a questi dati, con il meccanismo del rate limit.
Anche Facebook fornisce delle API, limitate e relative solo alle performance, pertanto le informazioni dei singoli profili non sono accessibili per vari motivi, uno fra tutti la privacy degli utenti.
Servizi sviluppati da terze parti.
E’ disponibile una grande varietà di applicazioni per il social media analytics, ovvero strumenti che consentono di raccogliere dati ed elaborare semplici metriche per poter effettuare analisi. Alcuni di questi servizi sono gratutiti o open source e hanno lo scopo di usare in maniera creativa le API delle piattaforme per testare un algoritmo, per sperimentare una visualizzazione, ecc. Ovviamente questi servizi, dato che incorporano nel loro codice le istruzioni delle API, hanno gli stessi limiti che queste impongono loro. Altre volte questi servizi sono a pagamento e sono pensati per finalità commerciali. In questo caso non hanno limiti attribuibili alle API, poiché hanno accordi commerciali con le singole piattaforme. Spesso questi servizi sono freemium, ovvero in parte gratutiti e in parte a pagamento. In questo modo è possibile usare la versione gratuita per sperimentare e passare alla versione a pagamento, quando si avrà bisogno di performances migliori.
Acquisto dei dataset direttamente dalle piattaforme di social media.
I vari social network mettono a disposizione direttamente o attraverso data reseller, i dataset ottenuti dai social media per poterli utilizzare per i propri scopi (di ricerca o di mercato). Esistono tre società che forniscono questo servizio, ognuna specializzata in uno specifico settore.
Gnip (http://gnip.com), recentemente acquisita dallo stesso Twitter, si tratta di una società specializzata nella vendita di dati relativi a Twitter e altre piattaforme (Tumblr, Foursquare, WordPress, Facebook, Google Plus, Youtube).
Datasift (http://datasift.com), che oltre a fornire dataset di tutti i principali servizi web fornisce anche dati relativi a social media cinesi (Sina Weibo, un SNS a metà tra Twitter e Facebook, Tencent Wibo, molto simile a Twitter).
Topsy (http://topsy.com) che fornisce accesso completo ai dati Twitter, consente anche di effettuare delle ricerche sui social media grazie alla sua applicazione che si presenta come un motore di ricerca per contenuti in tempo reale.
1.2 Twitter e il suo firehose
Il social media di maggior interesse per l’Analisi del Sentiment è senza dubbio Twitter, che offre un servizio completo che comprende API, servizi di terze parti, data reseller, partner certificati. Il flusso dati costante, relativo a tutti i tweet che vengono inviati nel web, è denominato: firehose.
L’utilizzo diretto del public stream di Twitter, direttamente dalle API, è attualmente gratuito, ma è limitato all’1% del volume totale di tweets generati (circa 60 messaggi al secondo). Per le modalità di accesso e acquisizione dei dati si consulti direttamente la documentazione ufficiale disponibile presso https://dev.twitter.com/streaming/overview.
In alternativa si può ottenere lo strem completo (oltre 6000 messaggi al secondo) attraverso l’offerta commerciale della piattaforma GNIP (http://gnip.com).
2. Tecnonologie di elaborazione dei dati
2.1 Elaborazione del sentiment con Apache Storm e Kafka
Sinonimo di gestione e analisi dei Big Data è oggi Apache Hadoop, la tecnologia studiata e messa a punto in più riprese da Google, Yahoo, Facebook, Twitter ed infine donata alla comunità open source.
L’originale orientamento di Hadoop all’elaborazione batch (modello Map/Reduce), negli ultimi anni è stato integrato ed affiancato da una serie di componenti (Yarn, Tez, Hive) che ne hanno aumentato la flessibilità e hanno reso disponibili funzionalità per l’elaborazione in-memory (Spark) e real-time (Storm, Kafka, Samza). In particolare il padadigma real time è la base per lo sviluppo delle infrastrutture IoT (Internet of Things) e per l’elaborazione dei flussi dei social network.
Nella progettazione di un’infrastruttura per la Sentiment Analysis la scelta privilegiata è rappresentata quindi dalla tecnologie Apache Storm e Kafka, che in seguito saranno brevemente descritte.
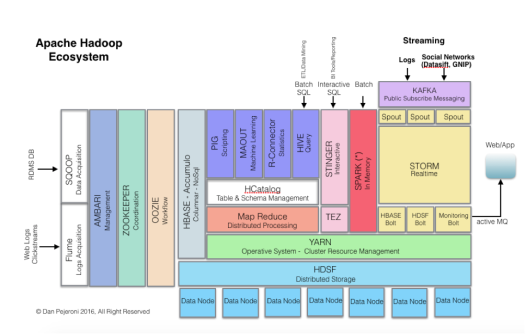
2.2 Apache Storm
Apache Storm è un ambiente di elaborazione veloce, scalabile che può essere programmato utilizzando una varietà di linguaggi. La sua architettura consiste in tre set di nodi primari:
Nodi Nimbus
Rappresentano i nodi master che caricano i calcoli che dovranno essere eseguiti nel cluster, lanciano i nodi di lavoro ed eventualmente li riassegnano in caso di errori. In un cluster esiste un solo nodo master.
Nodi Zookeeper
Questi nodi sono assegnati ad ogni macchina slave. La funzione di base dei nodi Zookeeper è il controllo dei nodi di lavoro. Nimbus comunica con i nodi di lavoro attraverso Zookeeper.
Nodi Supervisor
Il supervisor, avvia e arresta i worker nelle macchine slave in base ai comandi del nimbus. Una singola macchina slave può ospitare più nodi worker.
Una astrazione chiave in Storm è la topologia rappresentata dal progrmma che mantiene attivo il cluster Storm. E’ rappresentato visualmente da una rete di spout e bolt che Storm utilizza per eseguire i calcoli. Uno spout è uno stream di input che genera elementi denominati tuple. Per ricevere dati in real time, uno spout può essere configurato mediante un’API oppure un framework di code, come Kafka. Lo spout invia dati ai bolt dove vengono eseguiti i processi. Un cluster può essere costituito da diversi blot assegnati ai vari passi di processo per ottenere i risultati desiderati. I bolt possono trasferire dati ad altri bolt o ad un nodo di storage.
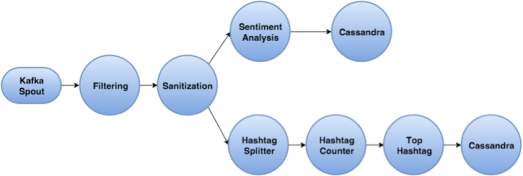
L’architettura elaborativa che utilizzeremo per il sentiment analysis è costituita dai seguenti componenti:
- Twitter Kafka producer: l’elemento che si occupa della lettura dei tweets dalla Twitter Streaming API, per la loro memorizzazione in Kafka;
- Twitter Storm Topology: una topologia Storm che legge i tweets da Kafka e, dopo aver applicato le regole di filtraggio e sanitarizzazione, processa i messagi in parallelo per la gestione della:
- Sentiment Analysis: utilizzando specifici algoritmi di sentiment analysis classifica i tweets in feeling positivi, negativi o neutri.
2.3 Apache Kafka
Apache Kafka è un sistema di messaggistica distribuito, che consente di creare applicazioni in tempo reale tramite flussi di dati. I flussi vengono inviati al cluster Kafka, che li memorizza nel buffer e li inoltra ad Apache Storm.
3. Opzioni per l’ambiente di elaborazione
Per la realizzazione dell’ambiente di elaborazione descritto nel precedente capitolo, abbiamo oggi alcune valide alternative, caratterizzate da differenti:
- livelli di investimento economico per la realizzazione dell’infrastruttura tecnologica;
- competenze tecniche necessarie per il suo avviamento e successiva gestione;
- oneri per la gestione e la manutenzione dell’impianto a regime.
Possiamo dividere queste soluzioni in due categorie principali:
- realizzazione di un’infrastruttura Hadoop in-house
- sottoscrizione di servizi Hadoop cloud
3.1 Realizzazione di un’infrastruttura Hadoop in-house
La migliore offerta di distribuzioni commerciali del framework Hadoop è oggi concentrata sui tre leader di mercato: Cloudera, Hortonworks e MapR.
L’analisi comparativa delle rispettive offerte esula dagli obiettivi di questo post e sarà approfondita in seguito. Ci limiteremo qui a fornire qualche considerazione generale per distinguere le diverse suite.
Tutti e tre i grandi player utilizzano il core framework Hadoop per fornirlo ad uso enterprise, includendo affidabili servizi di supporto.
Cloudera Distribution for Hadoop (CDH)
Cloudera è leader di mercato nel segmento Hadoop e sono stati i primi a rilasciare una distribuzione commerciale. Con oltre 350 clienti e con una attiva contribuzione di codice per l’ecosistema Hadoop, sono i primi quando si tratta di sviluppare tool innovativi. La loro console di management – Cloudera Manager – è facile da implementare e da utilizzare con una ricca interfccia utente che mostra tutte le informazioni in modo organizzato e chiaro. La suite Cludera Management automatizza anche i processi di installazione e fornisce molti servizi avanzati all’utente. Cloudera offre servizi di consulenza per colmare il gap tra ciò che la comunità fornisce e ciò di cui necessita l’organizzazione per integrare la tecnologia Hadoop nella sua strategia di data management. Per contro CDH è più lenta della distribuzione MapR.
MapR Hadoop Distribution
La distribuzione MapR Hadoop è basata sul concetto che un fornitore market driven deve supportare i bisogni del mercato velocemente. Aziende leader come Cisco, Ancestry.com, Boeing, Google Cloud Platform e Amazon EMR utilizzano MapR Hadoop Distribution per i loro servizi Hadoop. Diversamente da Cloudera e Hortonworks, MapR ha un approccio più distribuito per la memorizzazione dei metadata sui nodi di processo, poiché dipendono dal file system proprietario MapRFS, che non ha un’architettura NameNode.
Anche se attualmente la distribuzione MapR è posizionata in terza posizione in termini di numero di installazioni, è certamente, rispetto alle concorrenti, una delle più facili e performanti.
Hortonworks Data Platform (HDP)
Hortonworks, fondata da ex tecnici di Yahoo, fornisce un modello per Hadoop service only. Hortonworks è diversa dalle altre distribuzioni, essendo una open enterprise data platform disponibile in uso gratuito. La distribuzione Hortonworks HDP può essere facilmente scaricata e integrata per essere quindi utilizzata in varie applicazioni enterprise. Ebay, Samsung Electronics, Bloomberg and Spotify utilizzano HDP. Hortonworks è stato il primo vendor a fornire una distribuzione Hadoop 2.0 production ready. HDP è la sola distribuzione che supporta la piattaforma Windows. L’utente può quindi eseguire il deploy di un cluster Windows sul cloud Microsoft Azure, utilizzando il servizio HDInsight.
Sebbene i tre grandi vendor del mercato Hadoop siano caratterizzati da specifiche strategie e forniscano diverse funzionalità, non emerge un chiaro vincitore. Dovrà essere quindi fatta una scelta in relazione agli specifici requisiti di dettaglio. In termini generali possiamo concludere che MapR potrebbe rappresentare la strada giusta se l’impostazione open source è must aziendale, altrimenti la scelta dovrebbe orientarsi sulla suite di Hortonworks. In casi intermedi, le ottime caratteristiche della distribuzione Cloudera, potrebbe rappresentare il mix di funzionalità e facilità di gestione vincente.
Le alternative nella modalità di implementazione in house
Tutte e tre le distibuzioni descritte nei paragrafi precedenti sono disponibili nel formato macchina virtuale VmWare già configurate e praticamente pronte all’uso. Per la realizzazione di un prototipo per la Sentiment Analysis, è consigliabile avviare una fase di sperimentazione attraverso l’utilizzo di uno di questi ambienti:
MapR Sandbox https://www.mapr.com/products/mapr-sandbox-hadoop
Cloudera QuickStart http://www.cloudera.com/downloads/quickstart_vms/5-8.html
Hortonworks Sandbox http://it.hortonworks.com/products/sandbox/
L’avviamento delle macchine virtuali (che sono disponibili anche per VirtualBox e Docker) non richiede ambienti server particolarmente dotato di risorse. Sui siti non mancoano validi tutorial, che accompagnano le fasi di installazione, configurazione e primo utilizzo.
3.2 Utilizzo di Servizi di Cloud Computing
A causa della rapidissima evoluzione tecnologica, la maturità degli ambienti su cui costruire un’infrastruttura Big Data, rappresenta oggi un criterio incerto. Costruire e amministrare cluster Hadoop in produzione in modo affidabile ed efficiente, si può rivelare un compito complesso con numerosi fattori di rischio. Per questo l’offerta Cloud Computing è diventata nell’ultima decade uno standard de facto per la gestione dei flussi di lavoro dei Big Data.
Gli indiscussi leader di mercato del cloud computing, caratterizzati da una completa offerta Apache Hadoop, a cui rivolgersi per l’infrastruttura tecnologica sono:
- Google Cloud Platform (Cloud Dataproc)
- Amazon Web Services (Elastic MapReduce)
- Microsoft Azure (HDInsight)
Tutte e tre queste offerte consentono un rapidissimo deployment, una profonda integrazione con i sistemi di Cloud Storage e modelli di prezzo pay-only-for-what-you-use.
I tre sistemi forniscono una distribuzione dello stesso software open-source Hadoop. Le offerte EMR e Dataproc iniziano dalla distribuzione del repository Apache, per poi adattare una configurazione personalizzata della piattaforma cloud. HDInsight utilizza di base la piattaforma Hortonworks (HDP). Le differenze programmatiche e di esecuzione fra i tre sistemi derivano dalle differenze di versione dei pacchetti sorgenti.
HDInsight supporta la distribuzione di 17 diversi tipi di istanza di calcolo, che variano per prezzo e proprietà sistema quali core, RAM e la tecnologia disco. EMR, allo stesso modo, supporta 37 diversi tipi di istanza sottostanti. Dataproc supporta 19 tipi di istanza predefiniti e, in aggiunta, fornisce agli utenti infinite configurazioni personalizzate, per ottimizzare prestazioni e costi.
4. Strategie di Sentiment Analysis
4.1 Descrizione dei dati
I messaggi di Twitter sono limitati a 140 caratteri. A causa di questo limite gli utenti utilizzano frequentemente acronimi ed emoticons che esprimono le loro opinioni. Di seguito sono descritti gli elementi fondamentali di un tweet:
Hashtags
Il simbolo hashtag (#) è utilizzato per categorizzare il tweet in un dominio. E’ possibile utilizzare più hashtag in un singolo tweet.
es. #Independenceday : questo tag si riferisce al dominio
Independence Day, tutti i tweet che contengono questo hashtag saranno categorizzati in questo dominio.
Acronimi
I tweet che vengono postati non sempre sono costituiti da parole intere. Spesso vengono utilizzati abbreviazioni e acronimi per risparmiare caratteri. Nel corso dell’analisi questi acronimi devono essere espansi e analizzati, in quanto possono contenere una considerevole quantità di informazioni. Per questo scopo è necessario mantenere un dizionario separato degli acronimi:
es1. LOL : Risata. Categoria: Positiva
es2. Fab : Favoloso. Categoria: Positiva
es3. Plz : Per favore. Category: Neutra
Emoticon
Questi simboli vengono utilizzati per esprimere emozioni, in modo da mantenere conciso il tweet. Poiché gli emoticon rappresentano una significativa quantità di informazioni relative alla polarità del tweet, è necessario mantenere un dizionario dedicato.
es1. J Sorriso. Categoria: Positivo
es2. L Triste. Categoria: Negativo
es3. 😥 Piangere. Categoria: Negativo
URL
Le URL nei tweet vengono abbrevviate con degli URL shortners (es. Bit.ly
and tinyurl.com) allo scopo di contenerne la lunghezza. Questi URL
che puntano a citazioni esterne (gli URL vengono identificati dalla stringa “http://”, “https://” e www.)
es1. http://goo.gl/l6MS
Twitter Handles
Il simbolo @ viene utilizzato per citare un nome utente in un tweets: “Ciao
@DanPejeroni!” riferito anche come handle. Gli utenti utilizzano
@username per menzionare un altro utente in un tweet, inviare un
messaggio con un link ad un profilo.
Ripetizione di caratteri
Comunemente gli utenti enfatizzano i loro sentimenti nei tweet ripetendo alcuni caratteri. “@DanPejeroni oggi è stata una lungaaaaa giornata” Il termine “lungaaaa” è caratterizzato da una ripetizione di caratteri.
Parole intensificate:
Una parola in caratteri maiuscoli intensifica il proprio significato. “@DanPejeroni I
LOVE today’s weather.” Il termine LOVE è intensificato, quindi aiuta a comprendere la polarità del tweet.
4.2 Classificazione dei sentiment
I tweets sono scompost in token e assegnati ad una polarità (un numero a virgola mobile) compresa tra -1 e 1, dove -1 rappresenta un sentiment negativo, 0 neutro e 1 positivo. Il sentiment medio è quindi calcolato aggiungendo le polarità di ogni token. La somma viene quindi arrotondata all’intero più vicino, assegnando infine la polarità risultante al tweet.
Tweets positivi
- Tweets che indicano un successo o un festeggiamento
- Tweets di auguri o congratulazioni a qualcuno
- Tweets che utilizzano emoticons come 🙂 , 😀 , =) , =D, ^_^ , ❤
es.: Chasing 275 to win, India comfortably reached the target with 28 balls to spare due to some excellent batting from the top order. #IndvsSL
Tweets Negativi
- Tweet che indicano noia (es. se un film non è stato divertente)
- Tweet che indicano sconforto (es. a causa di una tragedia nella vita)
- Tweet che indicano ira (es. a causa di disordini in una zona)
- Tweet che utilizzano emoticon come 😦 , 😥 ,
 , -_-
, -_-
Tweets neutri
- Tweet che includono commenti sia negativi che positivi
- Tweet che non includono sentimenti nè positivi, né negativi
- Tweet che presentano fatti o teorie (es.: Ho studiato tutto il giorno, ho bisogno di aiuto!!!!)
4.3 Risorse
Per l’analisi dei tweet, utilizzeremo vari dizionari, dai quali può essere derivata la polarità. Normalmente vengono utilizzati quattro tipi di dizionari dedicati:
Dizionario lessicale
Faremo uso di un dizionario lessicale, dove sono riportati la maggior parte dei termini italiani. Questo dizionario ci aiuterà ad analizzare i tweet senza errori, facendo corrispondere le parole nel tweet con quelle del dizionario. Se un termine non viene trovato, controlleremo se se la parola contiene ripetizioni e sarà quindi categorizzata di conseguenza. Nel nostro sistema utilizzeremo il database Dante, che contiene lemmi, parole multiple, idiomi e frasi.
Dizionari di acronimi
Questo dizionario è utilizzato per espandere tutte le abbreviazioni e gli acronimi. Il processo di espansione degli acronimi genererà parole che richiedono ulteriori analisi utilizzando il dizionario lessicale per classificarle nelle polarità.
Dizionario degli emoticon
I tweet possono contenere emoticon utili a comprendere i sentimenti. Il dizionario degli emoticon svolge questo compito.
Dizionario delle Stop Word
In un tweet non tutte le parole hanno una polarità e non necessitano quindi di essere analizzate. Saranno quindi contrassegnate come stop word ed eliminate.
4.4 Processing dei dati
Suddivisione in token
Tutte le parole in un tweet devono essere suddivise in token. Per esempio ‘@DanPejeroni oggi ho passato una bellissima giornata!’ viene spezzata nei token ‘@DanPejeroni‘, ‘oggi’, ‘ho passato’, ‘una’, bellissima, ‘giornata’.
Emoticon, abbreviazioni, hashtag e URL vengono riconosciute come singoli token. Inoltre, ogni parola in un tweet è separata da uno spazio, quindi ad ogni spazio viene identificato, un nuovo token.
Normalizzazione
Inizialmente il processo di normalizzazione verifica ogni token e esegue alcuni calcoli specifici sulla sua tipologia:
- Se il token è un emoticon, gli viene attribuita una corrispondente polarità, in base al dizionario degli emoticon;
- Se il token è un acronimo, gli viene attribuita una corrispondente polarità, in base al dizionario degli acronimi
- Termini intensificati, come ‘SPENDIDO’ vengono convertite in lettere minuscole e il token è memorizzato come ‘I_spendido’. L’idea di base è quella di preservare l’enfasi dell’emozione dell’utente, codificandola con la codifica ‘I_’;
- Le sequenze di ripetizione di caratteri come ‘belloooo’ vengono corretti in ‘bello’ quindi memorizzati come ‘R_bello’. La codifica ‘R_’ è utilizzata con lo stesso scopo di quella ‘I_’;
- Il processo di normalizzazione elimina inoltre tutti i token che non contribuiscono al sentiment del tweet. Le Stop Word, come ‘questo’, ‘mentre’, ‘qundo, poichè non indicano alcun sentiment.quindi vengono eliminate. Similarmente le URL specified nel weet nei Twitter Handle possono essere sicuramente eliminate.
Analisi grammaticale
I token validi vengono passati al processo di analisi grammaticale che associa un tag (etichetta) ad ognuno di essi, specificando se si tratta di un sostantivo, verbo, avverbio, aggettivo, ecc. Il tagging relativo all’analisi grammaticale aiuta a determinare il sentiment complessivo del tweet in quanto i termini hanno un significato differente quando sono rappresentate come diverso elemento grammaticale. Per esempio, la parola ‘buono’ quando utilizzata come aggettivo, es. ‘vino buono’, esprime un sentiment positivo, dove lo stesso termine è usato come sostantivo in un contesto postale non indica tono né negativo, né positivo.
Implementazione
I Bolt sono componenti della topologia di Storm, che possono ricevere un input, processare i dati e inviare un output. Questo output può essere a sua volta inviato ad un altro Bolt o a una locazione di memorizzazione. In questa implementazione proponiamo di utilizzare sei Bolt, su ogni nodo worker. Lo stream di tweet ottenuto dallo Spout viene inviato al primo Bolt. Questo esegue la scomposizione in token che quindi invia al secondo Bolt, dove viene eseguito il processo di normalizzazione e solo i token validi vengono mantenuti. Gli elementi risultanti sono inviati al terzo Bolt, che realizza l’analisi grammaticale e il relativo processo di tagging. Sul quarto Bolt, a ogni token, viene assegnata la sua polarità, eseguendo la ricerca nei dizionari ed estraendo la sua corrispondente polarità a virgola mobile. La polarità complessiva di un tweet è quindi calcolata e inviata al quinto Bolt. Questo elemento di processo riceve le polarità di ogni tweet e calcola la sua media. Il valore medio è quindi passato al sesto Bolt, dove viene arrotondato al valore più vicino all’intero e rappresentato in forma di grafico o diagramma a torta.
4.5 Presentazione dei dati
Il risultato dell’elaborazione dei tweet su Apache Storm può essere prodotto in varie tipologie di output, per aiutare l’utente nell’analisi e nell’interpretazione del sentiment sui social media.
Grafici a torta
I grafici a torta o Graph Chart sono grafici circolari che rappresentano le statistiche in forma di settori percentili. Per esempio, il numero dei tweet che hanno una certa polarità saranno classificati in un settore della torta.
Timeline
Le timeline sono rappresentazioni della popolarità di un tweet o di una categoria di appartenenza. La durata del tempo può variare da un numero di ore in un dato giorno, a un numero di giorni di un dato mese.
Mappe
Le mappe mostrano un’area dove i tweet sono stati prodotti, eventualmente indicandone la polarità. Questo tipo di rappresentazione può risultare particolarmente utile per sondaggi locali, in quanto possono rappresentare la polarità in un’area in termini geografici. E’ possibile utilizzare la libreria Google Maps Javascript per la renderizzazione sulla mappa.

